// 用于 IE 的代码:
//if (window.ActiveXObject) //此方法判断ie11时会返回false
if ("ActiveXObject" in window)//故 改成这个判断
{
var xmlobject =new ActiveXObject("Microsoft.XMLDOM");
xmlobject.async="false";
xmlobject.loadXML("a.xml");
}else{
// 用于 Mozilla, Firefox, Opera, 等浏览器的代码:
var parser=new DOMParser();
var xmlobject =parser.parseFromString("a.xml","text/xml");
}
作者:壹零丶
Redis各数据类型及应用场景——哈希(Hash)
- Hashs
在Memcached中,我们经常将一些结构化的信息打包成hashmap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。
它是一个String类型的field和value的映射表,它的添加和删除都是平均的,hash特别适合用于存储对象,对于将对象存储成字符串而言,hash会占用更少的内存,并且可以更方便的存取整个对象.
使用场景:存储部分变更数据,如用户信息等
| 序号 | 命令及描述 |
|---|---|
| 1 | HDEL key field2 [field2] 删除一个或多个哈希表字段 |
| 2 | HEXISTS key field 查看哈希表 key 中,指定的字段是否存在。 |
| 3 | HGET key field 获取存储在哈希表中指定字段的值/td> |
| 4 | HGETALL key 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment 为哈希表 key 中的指定字段的整数值加上增量 increment 。 |
| 6 | HINCRBYFLOAT key field increment 为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 |
| 7 | HKEYS key 获取所有哈希表中的字段 |
| 8 | HLEN key 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| 11 | HSET key field value 将哈希表 key 中的字段 field 的值设为 value 。 |
| 12 | HSETNX key field value 只有在字段 field 不存在时,设置哈希表字段的值。 |
| 13 | HVALS key 获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] 迭代哈希表中的键值对 |
Redis各数据类型及应用场景——有序集合(sorted set)
- 有序集合(sorted set)
和Sets相比,Sorted Sets增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,比如一个存储全班同学成绩的Sorted Sets,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
使用场景:
a.排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
当用户登录时,对该用户的登录次数自增1;那么如何获得登录次数最多的用户呢,逆序排列取得排名前N的用户
b.需要精准设定过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
| 序号 | 命令及描述 |
|---|---|
| 1 | ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key 获取有序集合的成员数 |
| 3 | ZCOUNT key min max 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZINTERSTORE destination numkeys key [key …] 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 6 | ZLEXCOUNT key min max 在有序集合中计算指定字典区间内成员数量 |
| 7 | ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合成指定区间内的成员 |
| 8 | ZRANGEBYLEX key min max [LIMIT offset count] 通过字典区间返回有序集合的成员 |
| 9 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员 |
| 10 | ZRANK key member 返回有序集合中指定成员的索引 |
| 11 | ZREM key member [member …] 移除有序集合中的一个或多个成员 |
| 12 | ZREMRANGEBYLEX key min max 移除有序集合中给定的字典区间的所有成员 |
| 13 | ZREMRANGEBYRANK key start stop 移除有序集合中给定的排名区间的所有成员 |
| 14 | ZREMRANGEBYSCORE key min max 移除有序集合中给定的分数区间的所有成员 |
| 15 | ZREVRANGE key start stop [WITHSCORES] 返回有序集中指定区间内的成员,通过索引,分数从高到底 |
| 16 | ZREVRANGEBYSCORE key max min [WITHSCORES] 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 | ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 | ZSCORE key member 返回有序集中,成员的分数值 |
| 19 | ZUNIONSTORE destination numkeys key [key …] 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | ZSCAN key cursor [MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值) |
Redis各数据类型及应用场景——集合(Set)
- 集合(Set)
集合的概念就是一堆不重复值的组合。利用Redis提供的Set数据结构,可以存储一些集合性的数据。
Set是集合,是String类型的无序集合,set是通过hashtable实现的,概念和数学中个的集合基本类似,可以交集,并集,差集等等,set中的元素是没有顺序的。
应用场景:
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
| 序号 | 命令及描述 |
|---|---|
| 1 | SADD key member1 [member2] 向集合添加一个或多个成员 |
| 2 | SCARD key 获取集合的成员数 |
| 3 | SDIFF key1 [key2] 返回给定所有集合的差集 |
| 4 | SDIFFSTORE destination key1 [key2] 返回给定所有集合的差集并存储在 destination 中 |
| 5 | SINTER key1 [key2] 返回给定所有集合的交集 |
| 6 | SINTERSTORE destination key1 [key2] 返回给定所有集合的交集并存储在 destination 中 |
| 7 | SISMEMBER key member 判断 member 元素是否是集合 key 的成员 |
| 8 | SMEMBERS key 返回集合中的所有成员 |
| 9 | SMOVE source destination member 将 member 元素从 source 集合移动到 destination 集合 |
| 10 | SPOP key 移除并返回集合中的一个随机元素 |
| 11 | SRANDMEMBER key [count] 返回集合中一个或多个随机数 |
| 12 | SREM key member1 [member2] 移除集合中一个或多个成员 |
| 13 | SUNION key1 [key2] 返回所有给定集合的并集 |
| 14 | SUNIONSTORE destination key1 [key2] 所有给定集合的并集存储在 destination 集合中 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] 迭代集合中的元素 |
Redis各数据类型及应用场景——列表(List)
- 列表(List)
链表,略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。
使用场景:消息队列系统
比如sina微博:
在Redis中最新微博ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。数据库只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
| 序号 | 命令及描述 |
|---|---|
| 1 | BLPOP key1 [key2 ] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 2 | BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 3 | BRPOPLPUSH source destination timeout 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| 4 | LINDEX key index 通过索引获取列表中的元素 |
| 5 | LINSERT key BEFORE|AFTER pivot value 在列表的元素前或者后插入元素 |
| 6 | LLEN key 获取列表长度 |
| 7 | LPOP key 移出并获取列表的第一个元素 |
| 8 | LPUSH key value1 [value2] 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value 将一个或多个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop 获取列表指定范围内的元素 |
| 11 | LREM key count value 移除列表中与参数 VALUE 相等的元素 |
| 12 | LSET key index value 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 14 | RPOP key 移除并获取列表最后一个元素 |
| 15 | RPOPLPUSH source destination 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | RPUSH key value1 [value2] 在列表中添加一个或多个值 |
| 17 | RPUSHX key value 为已存在的列表添加值 |
Redis各数据类型及应用场景——字符串(String)
- 字符串(String)
使用场景:1.常规key-value缓存应用。2.常规计数: 微博数, 粉丝数
| 序号 | 命令及描述 |
|---|---|
| 1 | SET key value 设置指定 key 的值 |
| 2 | GET key 获取指定 key 的值。 |
| 3 | GETRANGE key start end 返回 key 中字符串值的子字符 |
| 4 | GETSET key value 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| 5 | GETBIT key offset 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 |
| 6 | MGET key1 [key2..] 获取所有(一个或多个)给定 key 的值。 |
| 7 | SETBIT key offset value 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 |
| 8 | SETEX key seconds value 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| 9 | SETNX key value 只有在 key 不存在时设置 key 的值。 |
| 10 | SETRANGE key offset value 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 |
| 11 | STRLEN key 返回 key 所储存的字符串值的长度。 |
| 12 | MSET key value [key value …] 同时设置一个或多个 key-value 对。 |
| 13 | MSETNX key value [key value …] 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| 14 | PSETEX key milliseconds value 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 |
| 15 | INCR key 将 key 中储存的数字值增一。 |
| 16 | INCRBY key increment 将 key 所储存的值加上给定的增量值(increment) 。 |
| 17 | INCRBYFLOAT key increment 将 key 所储存的值加上给定的浮点增量值(increment) 。 |
| 18 | DECR key 将 key 中储存的数字值减一。 |
| 19 | DECRBY key decrement key 所储存的值减去给定的减量值(decrement) 。 |
| 20 | APPEND key value 如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。 |
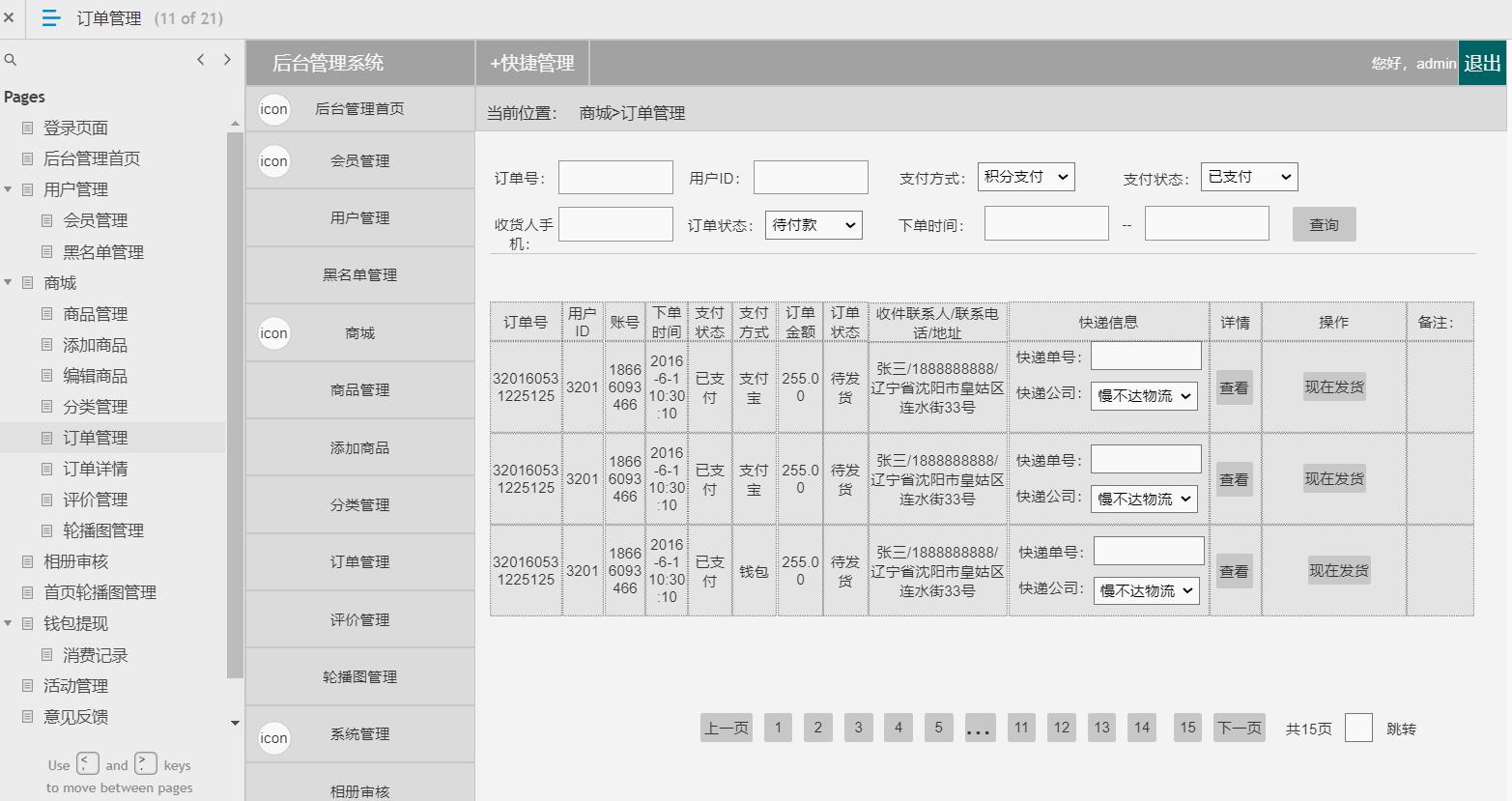
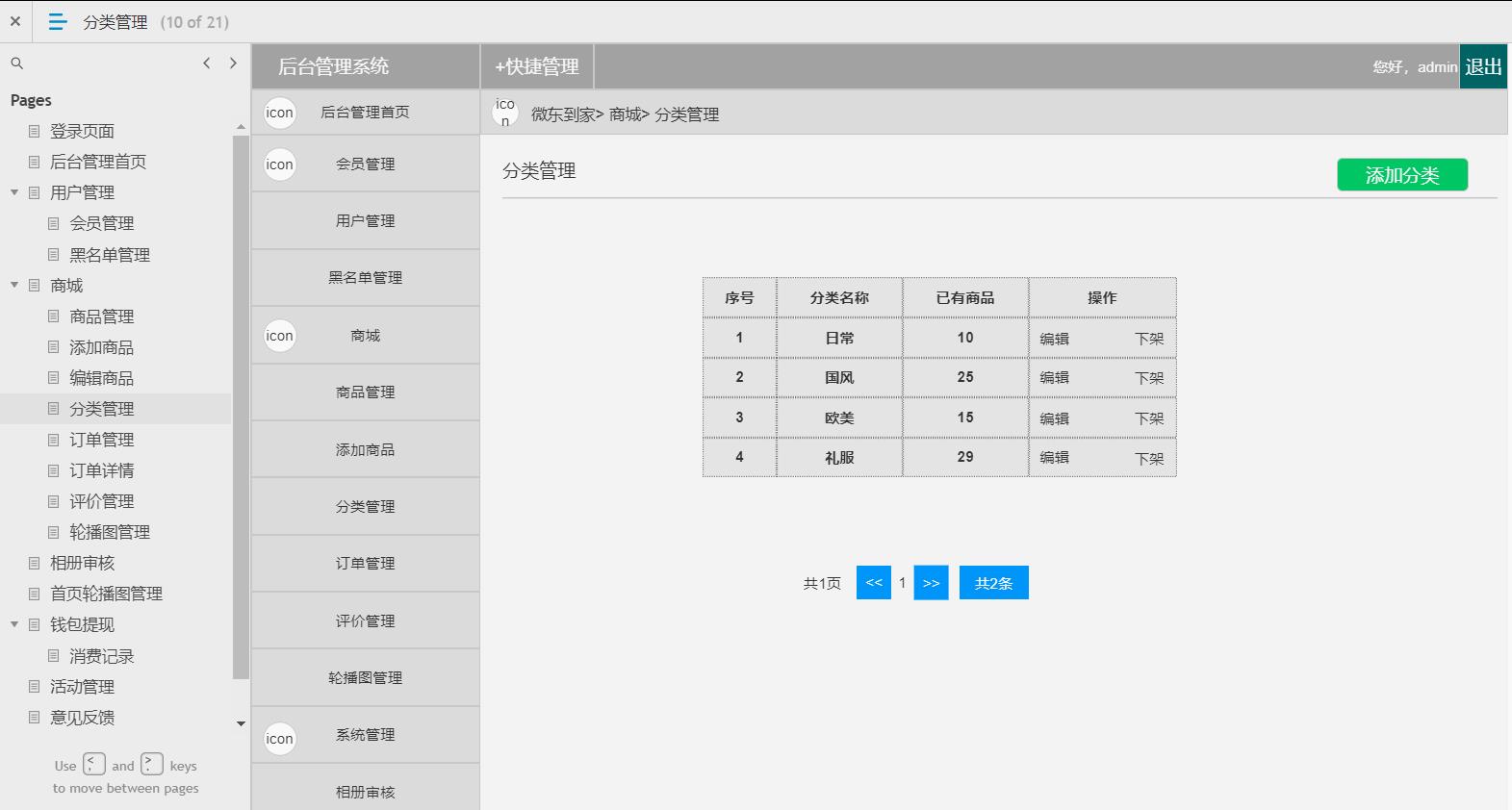
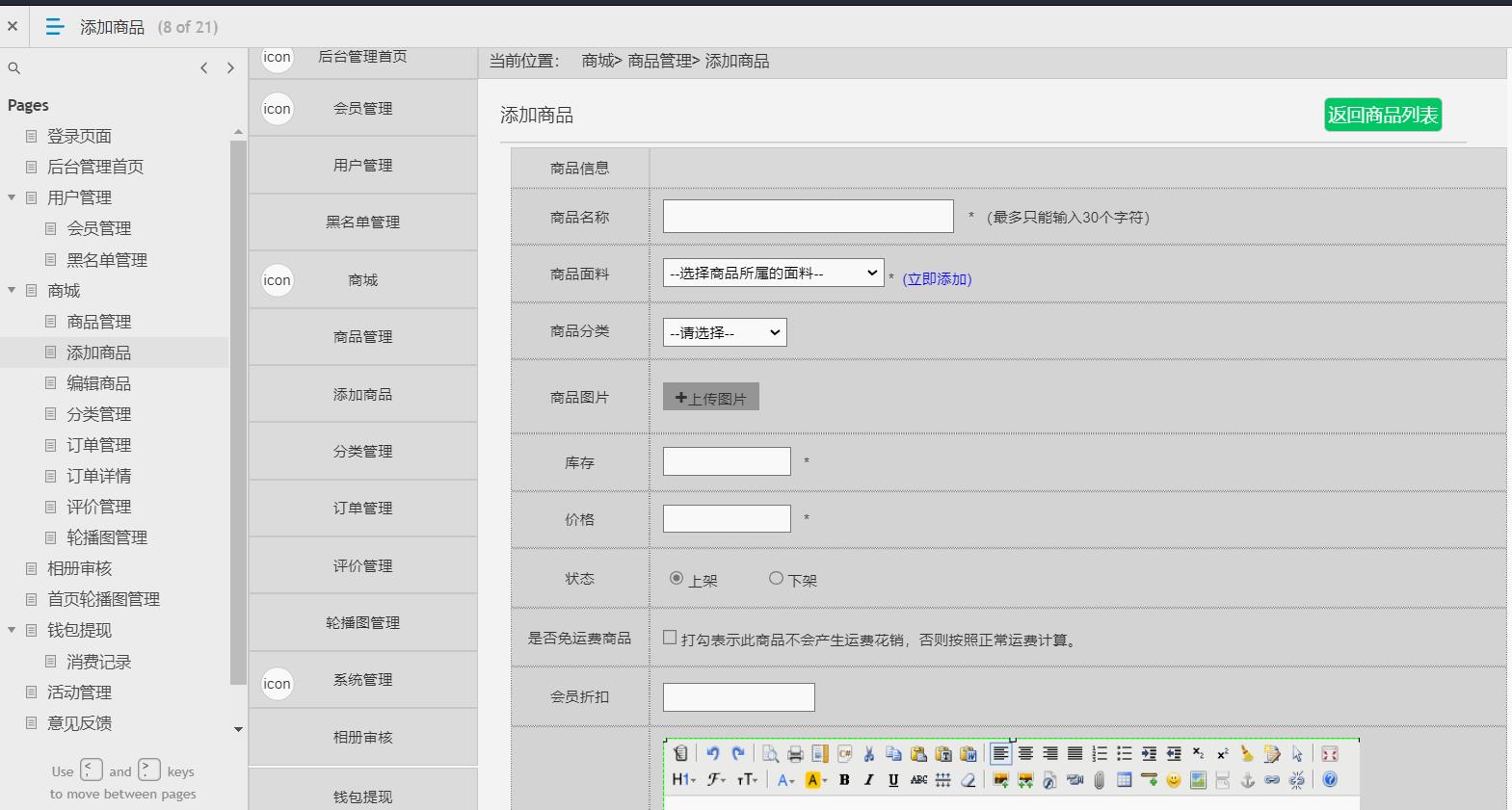
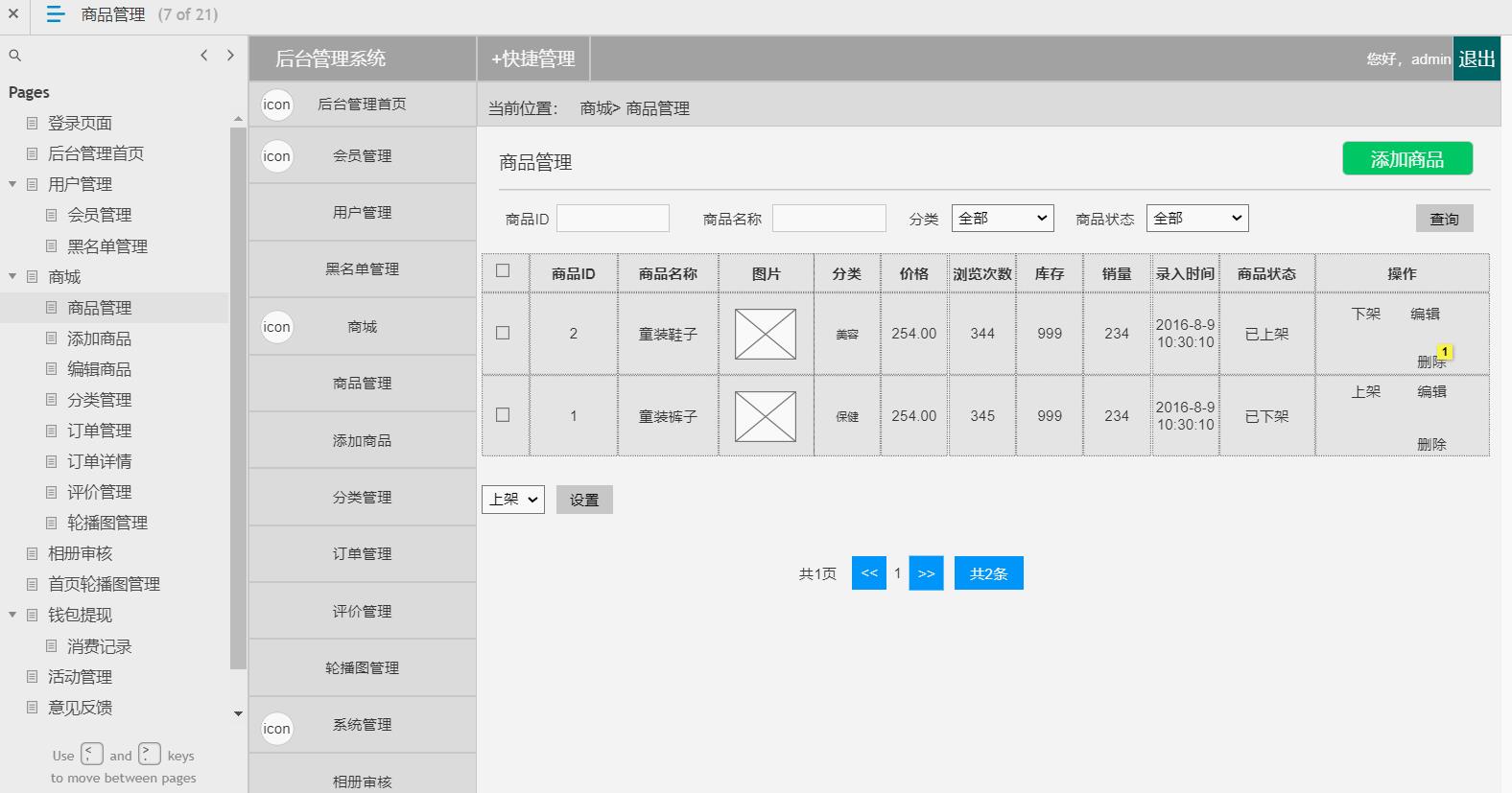
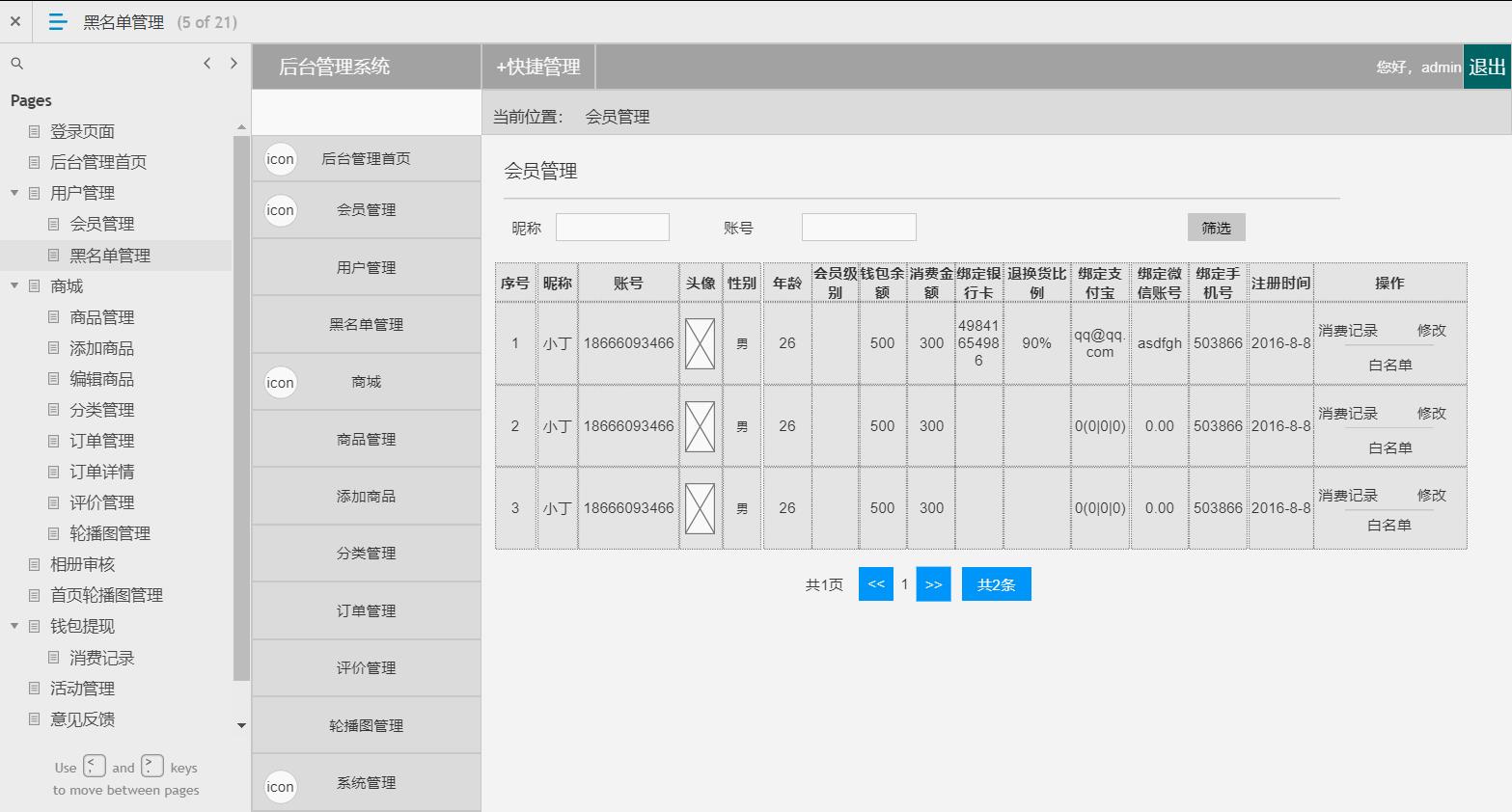
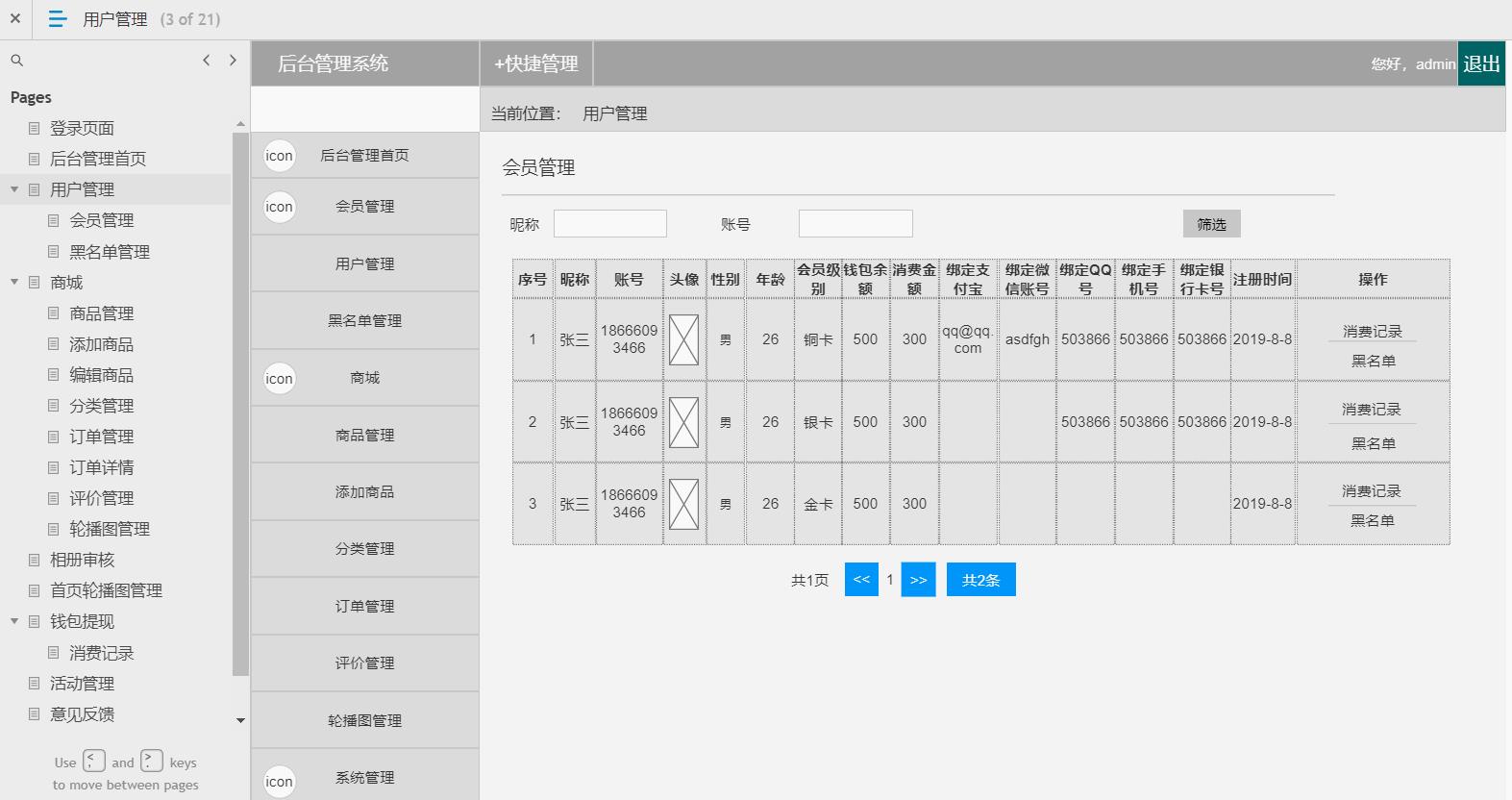
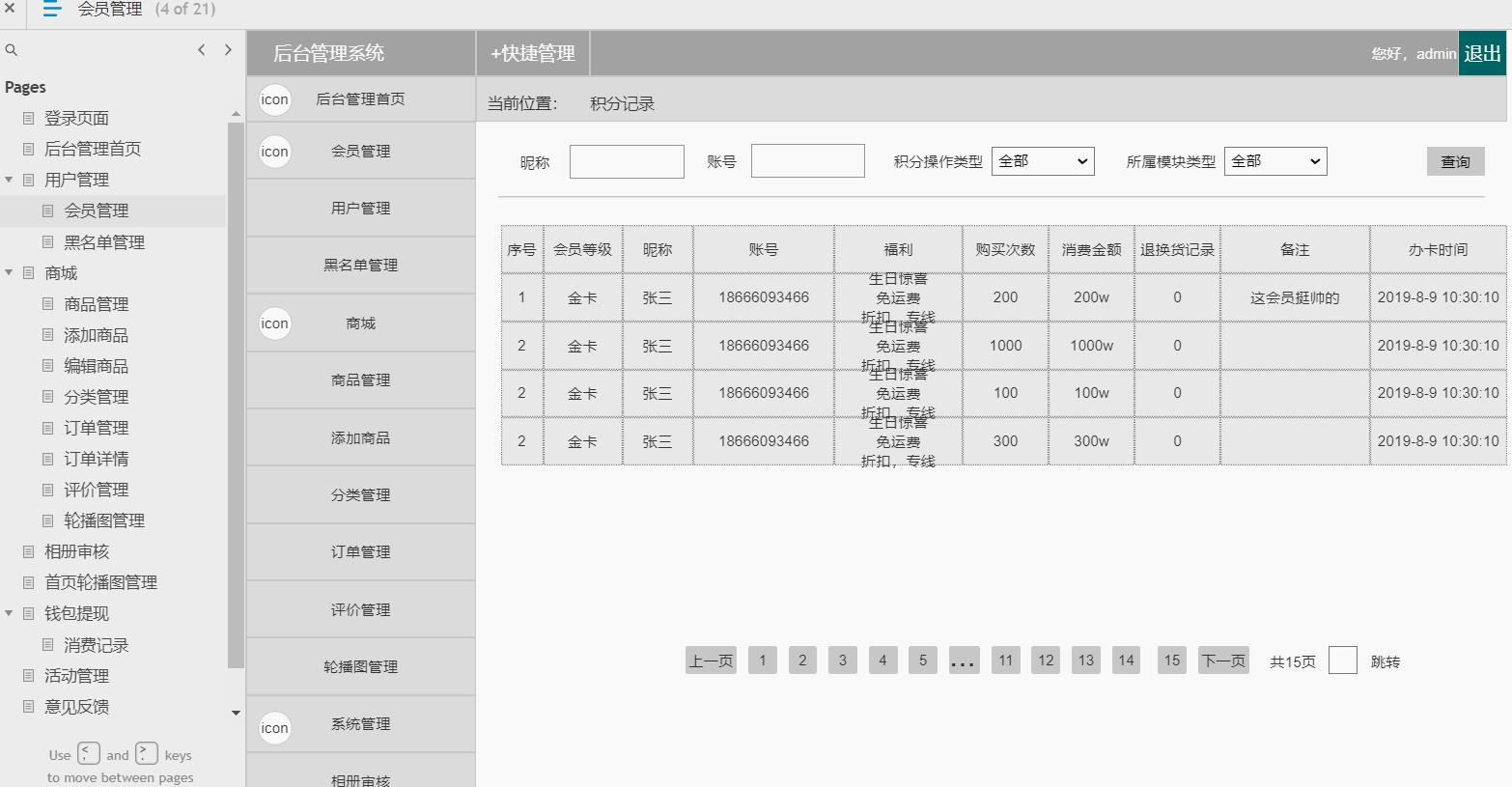
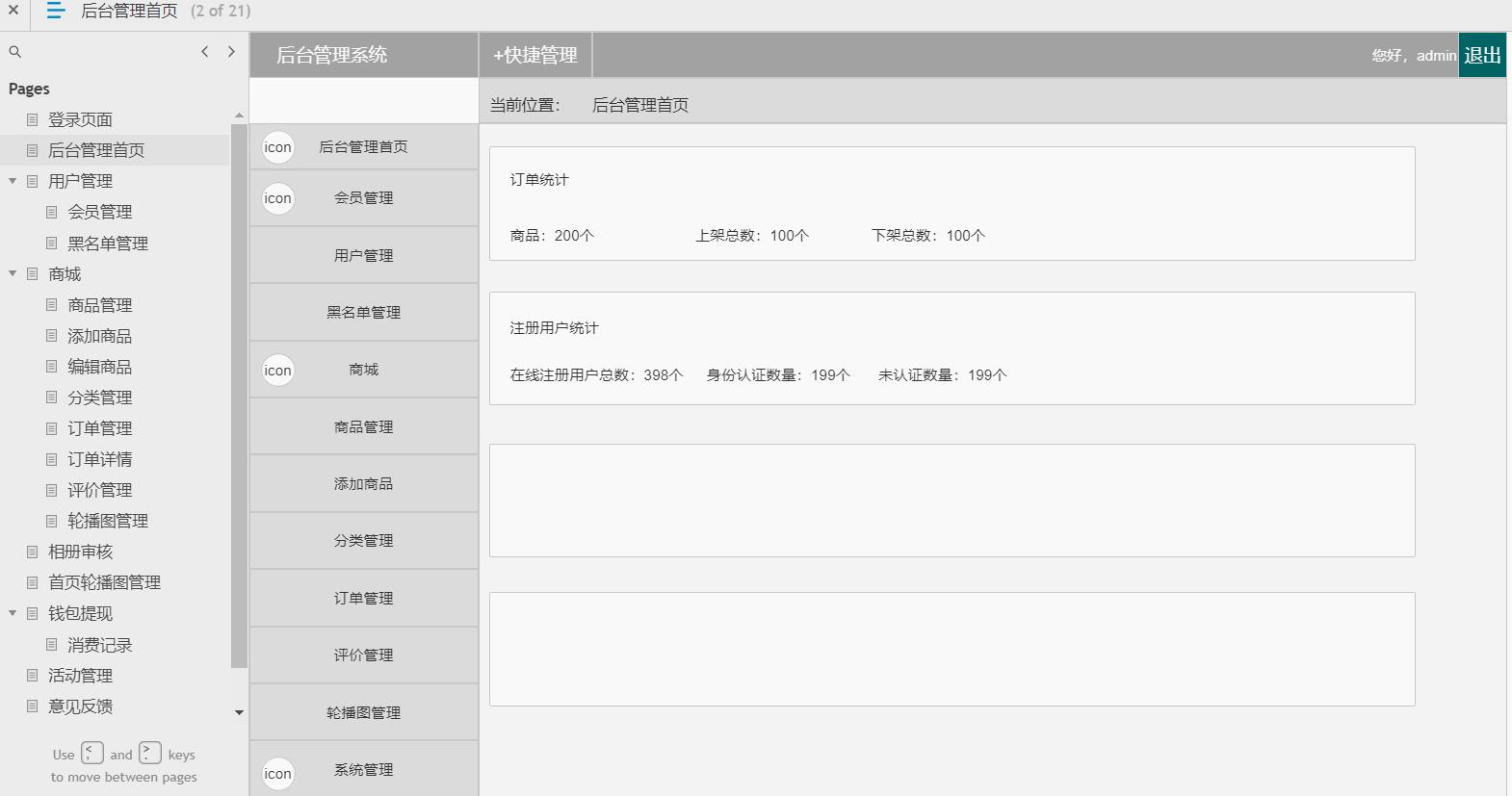
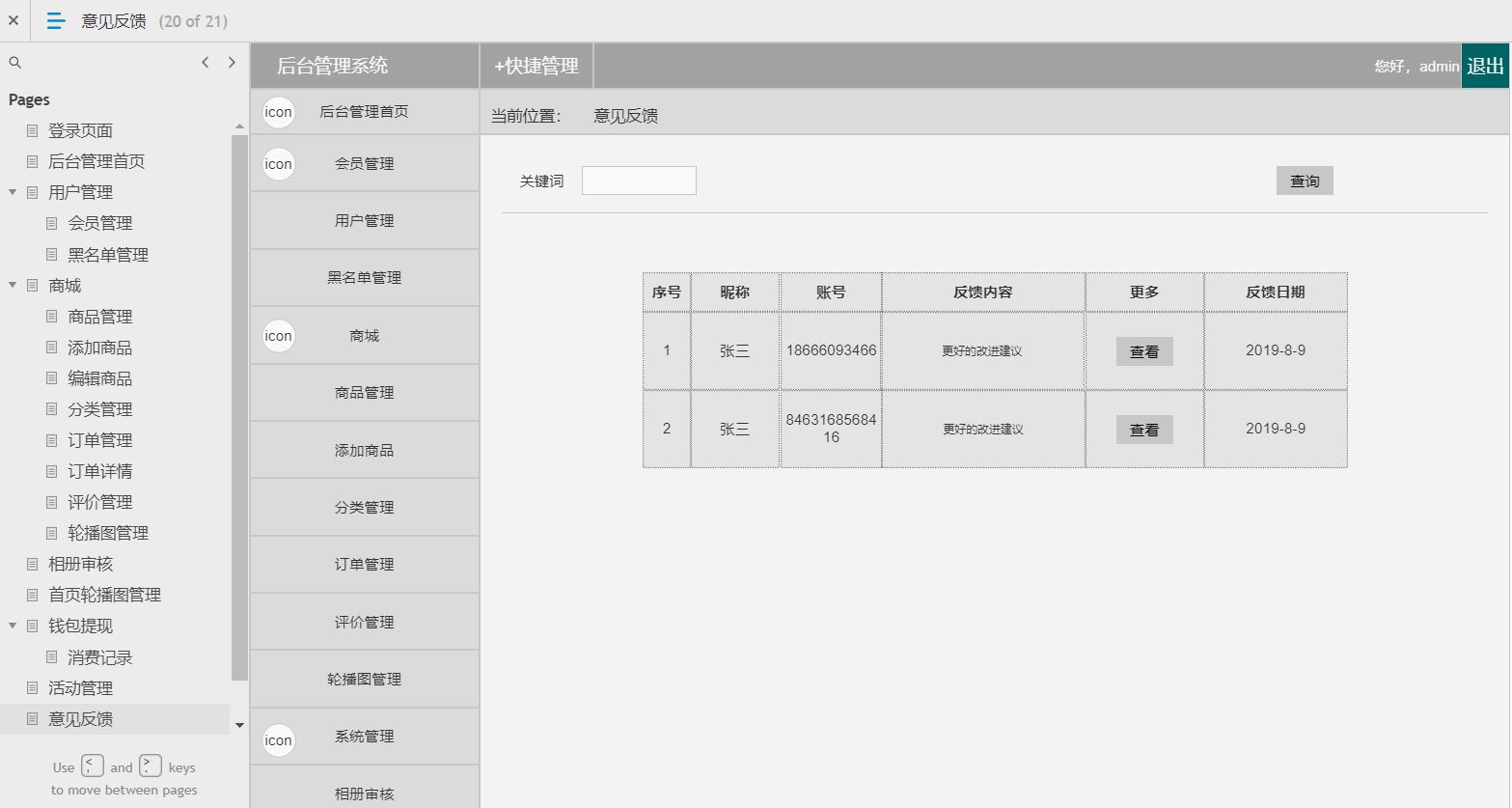
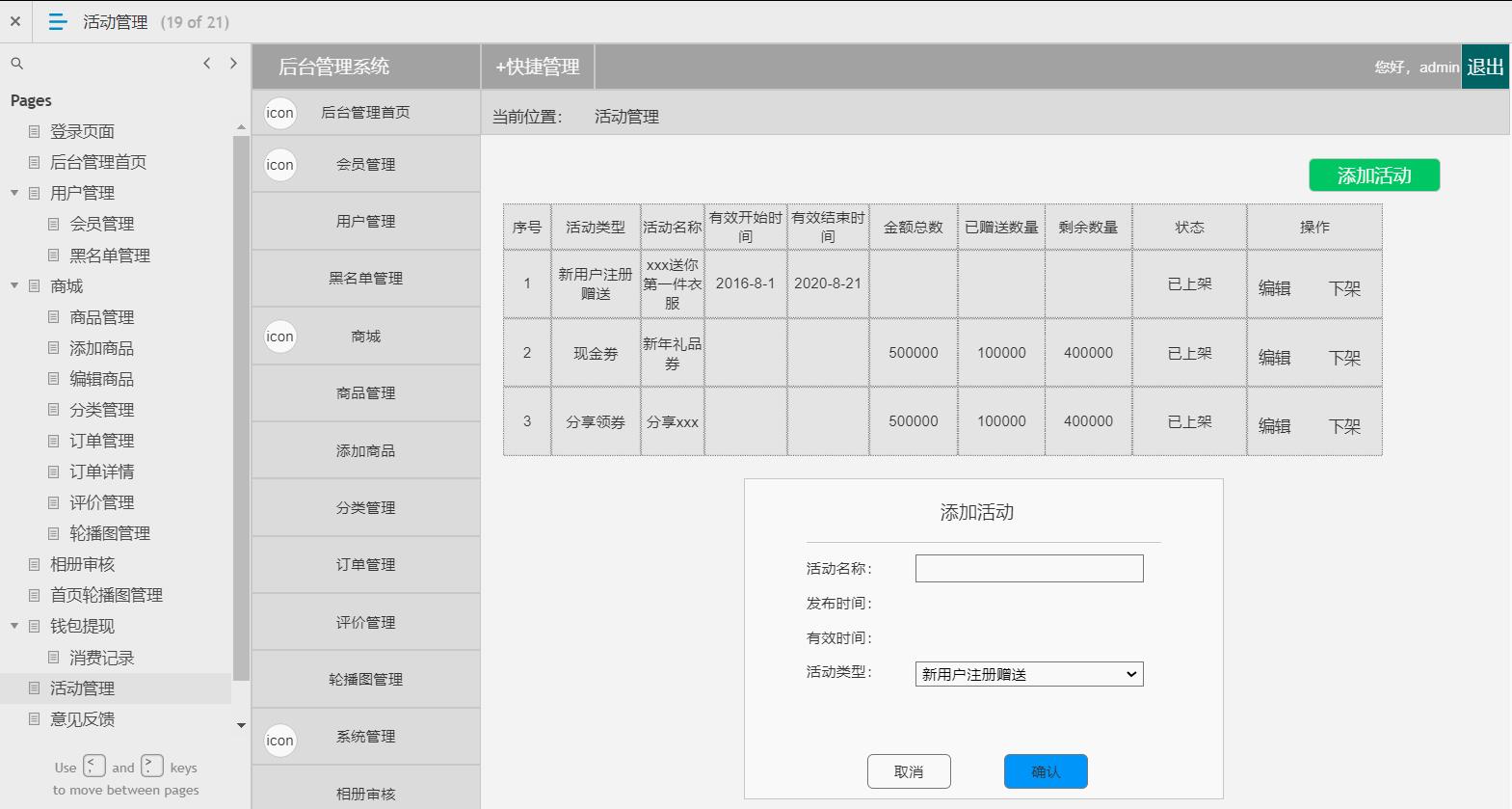
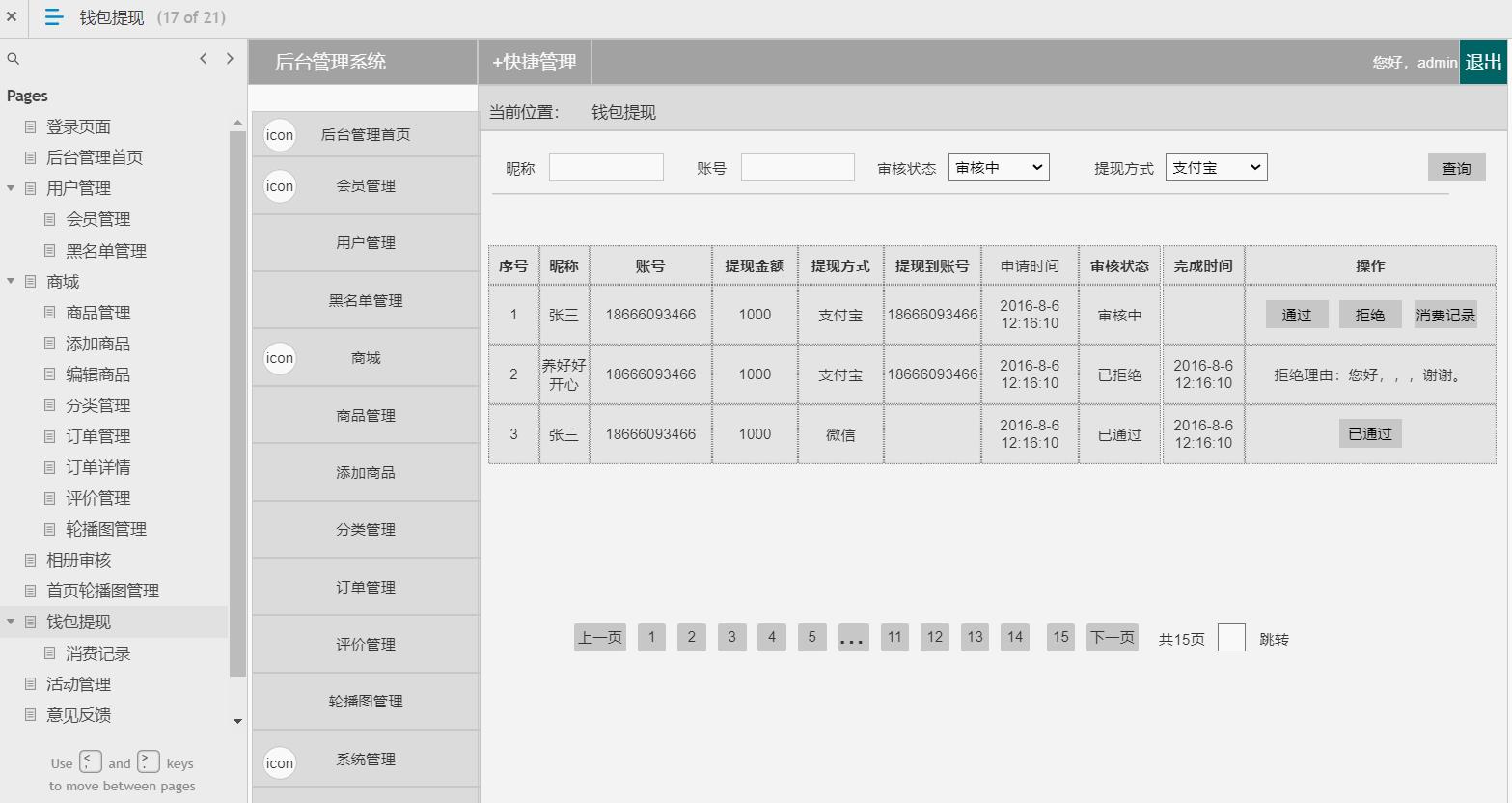
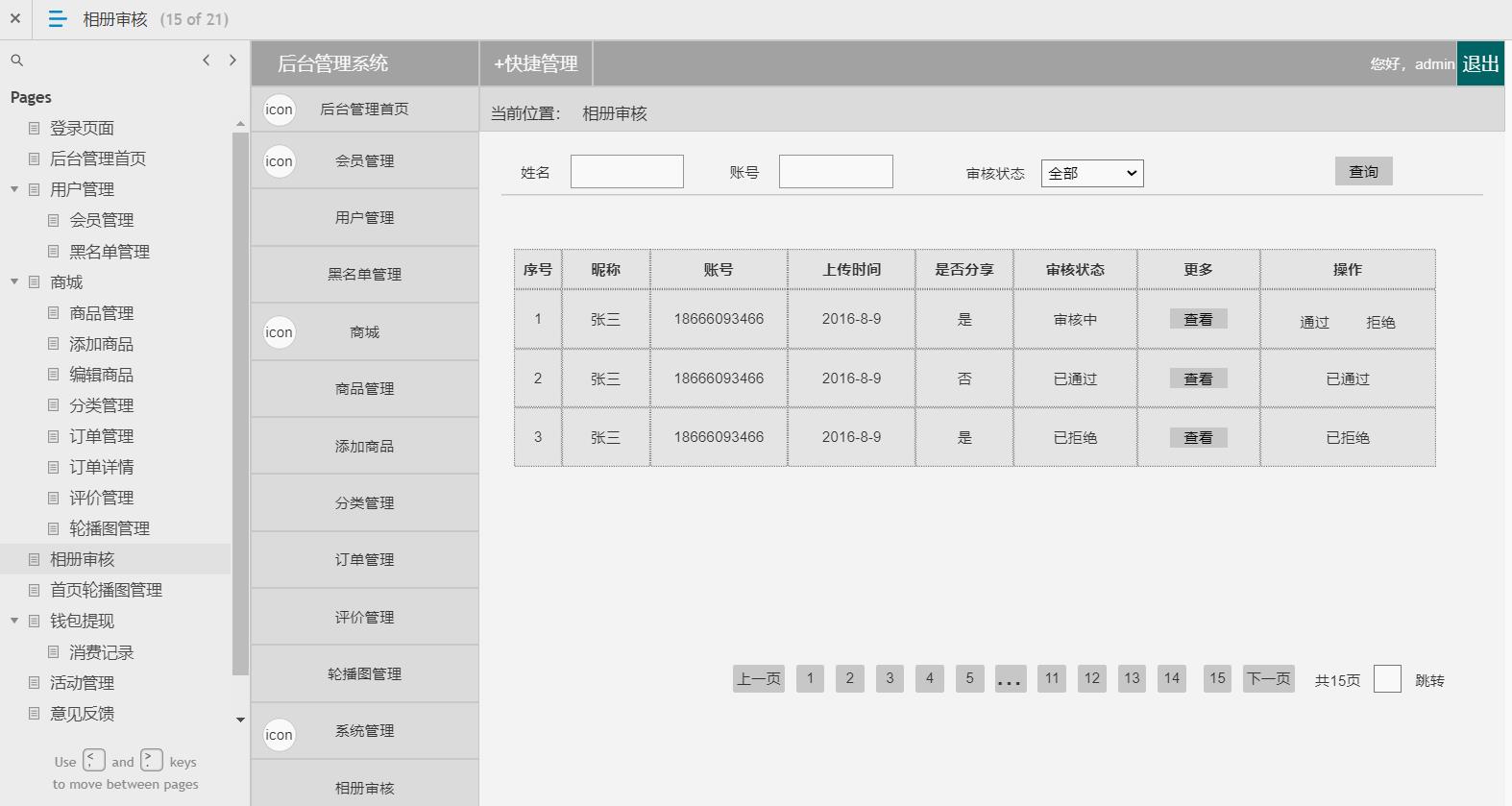
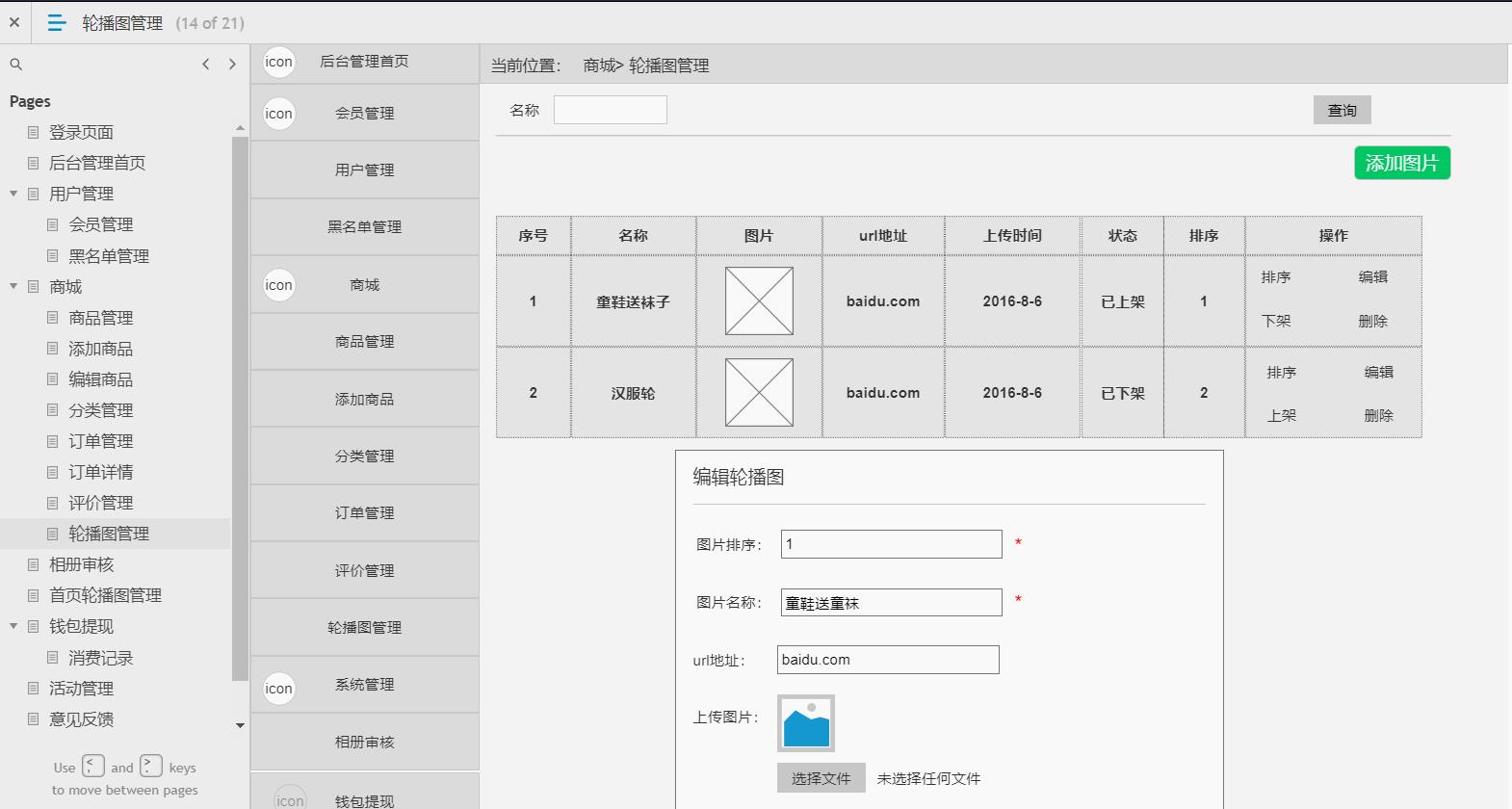
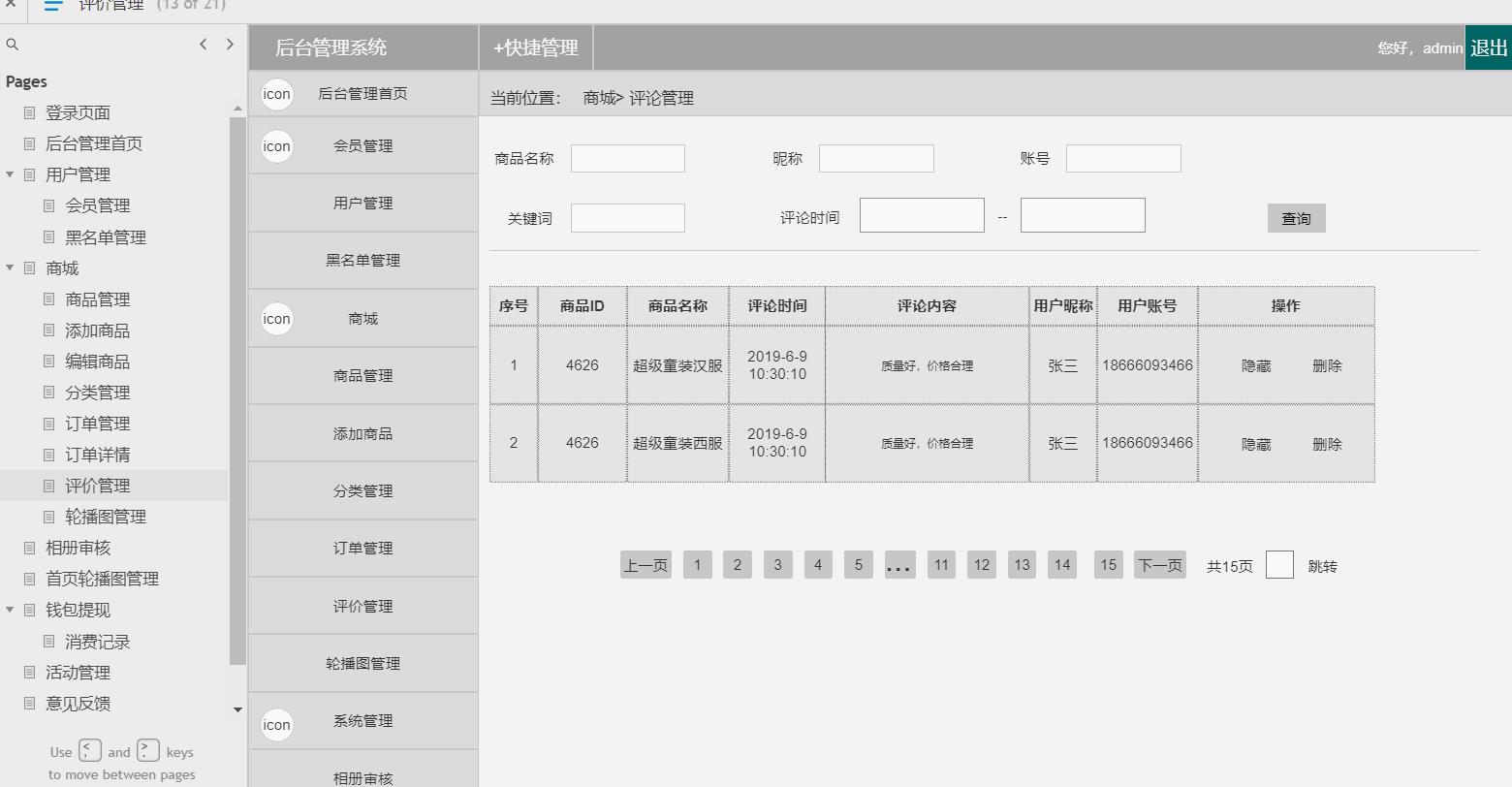
电商后台管理系统
包含:用户管理(会员管理,黑名单管理等),商场(商品管理,添加商品,编辑商品,商品分类,订单管理,订单详情,评价管理
,轮播图管理,相册审核),钱包体现(消费记录),活动管理,意见反馈,系统消息


redis和memcache选择
关于redis和memcache的不同,下面罗列了一些相关说法,供记录:
redis和memecache的不同在于:
- 存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化(笔者注:有快照和AOF日志两种持久化方式,在实际应用的时候,要特别注意配置文件快照参数,要不就很有可能服务器频繁满载做dump)。 - 数据支持类型:
redis在数据支持上要比memecache多的多。 - 使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
个人总结一下,有持久化需求或者对数据结构和处理有高级要求的应用,选择redis,其他简单的key/value存储,选择memcache。
MySql性能优化
- 为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
// 查询缓存不开启
$r=mysql_query("SELECT username FROM user WHERE date >= CURDATE()");
// 开启查询缓存
$today=date("Y-m-d");
$r=mysql_query("SELECT username FROM user WHERE date >= '$today'");
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
- EXPLAIN 你的 SELECT 查询
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。
查看key、rows列可以让我们找到潜在的性能问题。
- 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据
- 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
- 在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
// 在state中查找company
$r = mysql_query("SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id");
// 两个 state 字段应该是被建过索引的,而且应该是相当的类型,相同的字符集。
- 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录 :
// 千万不要这样做:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// 这要会更好:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
- 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。所以,你应该养成一个需要什么就取什么的好的习惯。
- 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的 AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要。
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
- 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
- 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
- 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值
- 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。
1 $r = “UPDATE users SET ip = INET_ATON(‘{$_SERVER[‘REMOTE_ADDR’]}’) WHERE user_id = $user_id”; - 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户 ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
- 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你的WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
while (1) {
//每次只做1000条
mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000");
if (mysql_affected_rows() == 0) {
// 没得可删了,退出!
break;
}
// 每次都要休息一会儿
usleep(50000);
}
- 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看。
- 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
linux SVN安装及配置
svn服务器有2种运行方式
1.独立服务器 (例如:svn://xxx.com/xxx);
2.借助apache。(例如:http://svn.xxx.com/xxx);
为了不依赖apache,选择第一种方式-独立的svn服务器。
编辑
1、查看是否安装了svn工具
命令:rpm -qa | grep subversion
如果服务器已经安装了则不需要进行安装,如果没有安装可以进行全新的安装
2、首先检测系统有没有安装SSL:
find / -name opensslv.h
如果找不到,就执行如下命令进行安装:
yum install openssl
yum install openssl-devel
安装之后用find / -name opensslv.h命令找到opensslv.h所在的目录,即下列–with-openssl=后面的路径,
3、解压svn安装文件
subversion-1.6.6.tar.gz
subversion-deps-1.6.6.tar.gz
命令如下:
|
1
2
|
tar zxvf subversion-1.6.6.tar.gztar zxvf subversion-deps-1.6.6.tar.gz |
tar 为解压命令,zxvf为tar命令的参数,用于解压tar.gz格式压缩的文件。
解压后生成 subversion-1.6.6 子目录,两个压缩包解压后都会自动放到此目录下,不用手动更改。
进入解压子目录 cd subversion-1.6.6 进行编译。
4、编译:
|
1
2
|
./configure --prefix=/usr/local/svn --with-openssl=/usr/include/openssl --without-berkeley-db |
后面以svnserve方式运行,所以不加apache编译参数。以fsfs格式存储版本库,不编译berkeley-db
如果编译时报如下错误:
no acceptable C compiler found in $PATH
说明没有gcc库,使用如下命令安装gcc后再编译:
yum -y install gcc
如果最后出现下面WARNING,我们直接忽略即可,因为不使用BDB存储。
|
1
2
3
4
5
6
7
|
configure: WARNING: we have configured without BDB filesystem supportYou don't seem to have Berkeley DB version 4.0.14 or newerinstalled and linked to APR-UTIL. We have created Makefiles whichwill build without the Berkeley DB back-end; your repositories willuse FSFS as the default back-end. You can find the latest version ofBerkeley DB here:http://www.sleepycat.com/download/index.shtml |
安装
make
make install
如果 make install 出现下面错误:
/home/upload/subversion-1.6.6/subversion/svnversion/.libs/lt-svnversion: error while loading shared libraries: libiconv.so.2: cannot open shared object file: No such file or directory
make: *** [revision-install] Error 127
解决办法:
1、编辑/etc/ld.so.conf文件
vi /etc/ld.so.conf
添加下面一行代码
/usr/local/lib
2、保存后运行ldconfig:
/sbin/ldconfig
注:ld.so.conf和ldconfig用于维护系统动态链接库。
3、然后再安装
make && make install
测试是否安装成功
|
1
|
/usr/local/svn/bin/svnserve --version |
如果显示如下,svn安装成功:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
svnserve, version 1.6.6 (r40053) compiled Dec 25 2012, 13:14:38Copyright (C) 2000-2009 CollabNet.Subversion is open source software, see http://subversion.tigris.org/This product includes software developed by CollabNet (http://www.Collab.Net/).The following repository back-end (FS) modules are available:* fs_fs : Module for working with a plain file (FSFS) repository.Cyrus SASL authentication is available. |
4、为了方便下操作,把svn相关的命令添加到环境变量中:
echo “export PATH=$PATH:/usr/local/svn/bin/” >> /etc/profile
source /etc/profile
配置svn
1、建立SVN的根目录
mkdir -p /opt/svn/
2、建立一个产品仓库
mkdir -p /opt/svn/tshop/
svnadmin create /opt/svn/tshop/
如果你们的研发中心有多个产品组,每个产品组可以建立一个SVN仓库
3、修改版本配置库文件
vi /opt/svn/tshop/conf/svnserve.conf
修改后的文件内容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
### This file controls the configuration of the svnserve daemon, if you### use it to allow access to this repository. (If you only allow### access through http: and/or file: URLs, then this file is### irrelevant.)### Visit http://subversion.tigris.org/ for more information.[general]### These options control access to the repository for unauthenticated### and authenticated users. Valid values are "write", "read",### and "none". The sample settings below are the defaults.anon-access = none # 注意这里必须设置,否则所有用户不用密码就可以访问auth-access = write### The password-db option controls the location of the password### database file. Unless you specify a path starting with a /,### the file's location is relative to the directory containing### this configuration file.### If SASL is enabled (see below), this file will NOT be used.### Uncomment the line below to use the default password file.password-db = passwd### The authz-db option controls the location of the authorization### rules for path-based access control. Unless you specify a path### starting with a /, the file's location is relative to the the### directory containing this file. If you don't specify an### authz-db, no path-based access control is done.### Uncomment the line below to use the default authorization file.authz-db = authz### This option specifies the authentication realm of the repository.### If two repositories have the same authentication realm, they should### have the same password database, and vice versa. The default realm### is repository's uuid.realm = tshop[sasl]### This option specifies whether you want to use the Cyrus SASL### library for authentication. Default is false.### This section will be ignored if svnserve is not built with Cyrus### SASL support; to check, run 'svnserve --version' and look for a line### reading 'Cyrus SASL authentication is available.'# use-sasl = true### These options specify the desired strength of the security layer### that you want SASL to provide. 0 means no encryption, 1 means### integrity-checking only, values larger than 1 are correlated### to the effective key length for encryption (e.g. 128 means 128-bit### encryption). The values below are the defaults.# min-encryption = 0# max-encryption = 256 |
对用户配置文件的修改是立即生效的,不必重启svn。
4、开始设置passwd用户账号信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
vi /data/svn/repos/conf/passwd修改完之后的内容如下:### This file is an example password file for svnserve.### Its format is similar to that of svnserve.conf. As shown in the### example below it contains one section labelled [users].### The name and password for each user follow, one account per line.### 在下面添加用户和密码,每行一组username = password[users]# harry = harryssecret# sally = sallyssecret###===========下面是我添加的用户信息========#######iitshare = password1itblood = password2 |
5、开始设置authz. 用户访问权限
vi /data/svn/repos/conf/authz
修改完之后的内容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
### This file is an example authorization file for svnserve.### Its format is identical to that of mod_authz_svn authorization### files.### As shown below each section defines authorizations for the path and### (optional) repository specified by the section name.### The authorizations follow. An authorization line can refer to:### - a single user,### - a group of users defined in a special [groups] section,### - an alias defined in a special [aliases] section,### - all authenticated users, using the '$authenticated' token,### - only anonymous users, using the '$anonymous' token,### - anyone, using the '*' wildcard.###### A match can be inverted by prefixing the rule with '~'. Rules can### grant read ('r') access, read-write ('rw') access, or no access### ('').[aliases]# joe = /C=XZ/ST=Dessert/L=Snake City/O=Snake Oil, Ltd./OU=Research Institute/CN=Joe Average# [groups]# harry_and_sally = harry,sally# harry_sally_and_joe = harry,sally,&joe# [/foo/bar]# harry = rw# &joe = r# * =# [repository:/baz/fuz]# @harry_and_sally = rw# * = r###--------------------下面我新加的------------------------######屏蔽掉上面的[groups] 因为在下面添加了[groups]devteam = iitshare, itblood #devteam 项目组包括两个用户iitshare,itblood[/]iitshare = rwitblood =[tshop:/tb2c]@devteam = rwitblood =[tshop:/tb2b2c]@devteam = rwitblood = r |
其中,1个用户组可以包含1个或多个用户,用户间以逗号分隔。
说明:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
devteam = iitshare, itblood #devteam 项目组包括两个用户iitshare,itblood[/]iitshare = rw #iitshare 对根目录有读写权限itblood = #itblood 对根目录没有任何权限####如果需要配置tb2c、tb2b2c项目的权限,前提条件是tshop仓库下面需要有这两个项目####如果没有的话,tshop都将不能访问[tshop:/tb2c] #对tshop仓库的tb2c项目进行权限控制@devteam = rw #控制 devteam 组对tb2c项目有读写权限itblood = #限制 itblood 所有权限,其它用户有读写权限[tshop:/tb2b2c] #对 tshop: 仓库的 tb2b2c 项目进行权限控制@devteam = rw #限制 devteam 组对tb2b2c项目有读写权限itblood = r #限制 itblood 只有读权限,其它用户有读写权限 |
6、注意:
* 权限配置文件中出现的用户名必须已在用户配置文件中定义。
* 对权限配置文件的修改立即生效,不必重启svn。 * 配置行前面不能有空格
用户组格式:
|
1
2
3
4
5
6
7
|
[groups]= ,其中,1个用户组可以包含1个或多个用户,用户间以逗号分隔。版本库目录格式:[<版本库>:/项目/目录]@<用户组名> = <权限><用户名> = <权限> |
其中,方框号内部分可以有多种写法:
[/],表示根目录及以下,根目录是svnserve启动时指定的,我们指定为/home/svndata,[/]就是表示对全部版本库设置权限。
[tshop:/] 表示对版本库tshop设置权限;
[tshop:/abc] 表示对版本库tshop中的abc项目设置权限;
[tshop:/abc/aaa] 表示对版本库tshop中的abc项目的aaa目录设置权限;
权限主体可以是用户组、用户或*,用户组在前面加@,*表示全部用户。
权限可以是w、r、wr和空,空表示没有任何权限。
7、建立启动svn的用户
useradd svn
根据提示,为用户svn设置密码
允许用户svn访问版本库:
chown -R svn:svn /opt/svn
8、启动svn:
方式一:svnserve -d -r /opt/svn/ #默认的启动端口号为3690
方式二:su – svn -c “svnserve -d –listen-port 9999 -r /opt/svn/”
其中:
su – svn表示以用户svn的身份启动svn;
-d表示以daemon方式(后台运行)运行;
–listen-port 9999表示使用9999端口,可以换成你需要的端口。但注意,使用1024以下的端口需要root权限;
-r /opt/svn 指定根目录是/opt/svn。
9、检查是否启动
netstat -tunlp | grep svn
如果显示以下信息说明启动成功
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 10973/svnserve
10、将svn加入到开机启动
编辑rc.local文件:vi /etc/rc.d/rc.local
加入如下启动命令:
/usr/local/svn/bin/svnserve -d –listen-port 9999 -r /opt/svn
11、如果想停止svn,则使用如下命令:
killall svnserve
12、如果想将svn作为服务:
在/etc/rc.d/init.d/目录下新建名为svn的文件
并设置权限为755:chmod 755 /etc/rc.d/init.d/svn
编辑svn文件:vi /etc/rc.d/init.d/svn, 在里面添加如下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#!/bin/bash# build this file in /etc/rc.d/init.d/svn# chmod 755 /etc/rc.d/init.d/svn# centos下可以用如下命令管理svn: service svn start(restart/stop)SVN_HOME=/opt/svnif [ ! -f "/usr/local/svn/bin/svnserve" ]then echo "svnserver startup: cannot start" exitficase "$1" in start) echo "Starting svnserve..." /usr/local/svn/bin/svnserve -d --listen-port 9999 -r $SVN_HOME echo "Finished!" ;; stop) echo "Stoping svnserve..." killall svnserve echo "Finished!" ;; restart) $0 stop $0 start ;; *) echo "Usage: svn { start | stop | restart } " exit 1esac |
之后便可以以service svn start(restart/stop)方式启动SVN。
客户端访问
地址如下:
svn://{your-server-ip}:9999/tshop/ 或者 svn://{your-server-ip}:3690/tshop/
注意:
不要在浏览器中通过http的方式进行访问,如下地址:
http://{your-server-ip}:9999/tshop/ 或者 http://{your-server-ip}:3690/tshop/
那样肯定是不行的,因为你没有配置http的服务,上面是安装独立的SVN服务器